
東海道五十三次のルートは、日本橋(江戸)〜三条大橋(京)の全長約490kmの街道です。
江戸時代の人は、徒歩で約二週間かけて旅していたとのこと。一日の移動距離は平均すると35km(一歩が70cmとすると5万歩)となります。すごいですね。
私もその昔、東海道五十三次を自転車でトライしたのですが、小田原〜箱根間で転倒し、箱根の坂を前に挫折しました。
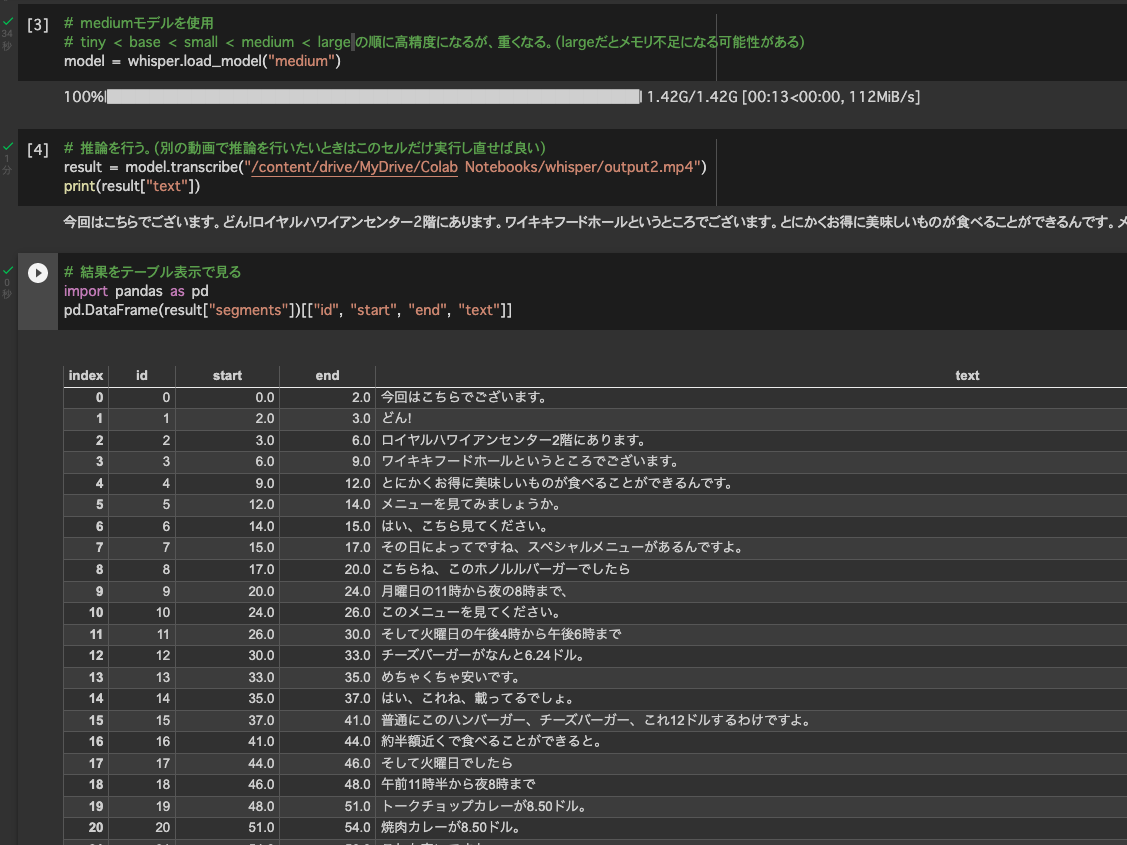
今回、Pythonで再チャレンジしたいと思います。
1. モジュールのインポート
import folium
from folium.features import DivIcon
from folium import plugins
shukuba_list = \
[['日本橋',139.774444444444,35.6836111111111],
['品川宿',139.739166666667,35.6219444444444],
['川崎宿',139.707777777778,35.5355555555556],
['神奈川宿',139.632277777778,35.4727777777778],
['保ヶ谷宿',139.595555555556,35.4440277777778],
['戸塚宿',139.529861111111,35.3950277777778],
['藤沢宿',139.486305555556,35.3456666666667],
['平塚宿',139.337805555556,35.3272777777778],
['大磯宿',139.315305555556,35.309],
['小田原宿',139.161027777778,35.2487222222222],
['箱根宿',139.026361111111,35.1904166666667],
['三島宿',138.914472222222,35.11925],
['草津宿',135.960638888889,35.0174444444444],
['大津宿',135.861416666667,35.0059722222222],
['三条大橋',135.774361111111,35.0103333333333]]
※緯度・経度の引用元
東海道五十三次 - Wikipedia
3. 地図を作成
tokaido_map = folium.Map(location=[35.360626, 138.727363], zoom_start=8, tiles='stamenterrain')
for i in range(len(shukuba_list)):
length=len(shukuba_list[i][0])
if i == 0 or i == 54:
folium.Marker(location=[shukuba_list[i][2], shukuba_list[i][1]], icon=DivIcon(
icon_size=(25, 25),
icon_anchor=(0, 0),
html='<div style="text-align: center; font-size: 11pt; color : black width: 25px; height: 25px; background: skyblue; border:2px solid #666; border-radius: 50%; ">'+"★"+'</div>'),
popup=shukuba_list[i][0]+(' '*length)).add_to(tokaido_map)
else:
folium.Marker(location=[shukuba_list[i][2], shukuba_list[i][1]], icon=DivIcon(
icon_size=(25, 25),
icon_anchor=(0, 0),
html='<div style="text-align: center; font-size: 11pt; color : black width: 25px; height: 25px; background: skyblue; border:2px solid #666; border-radius: 50%; ">'+str(i)+'</div>'),
popup=str(i)+'.'+shukuba_list[i][0]+(' '*(length+1))).add_to(tokaido_map)
4. フルスクリーン機能を追加
plugins.Fullscreen(
position="topright",
title="拡大する",
title_cancel="元に戻す",
force_separate_button=True,
).add_to(tokaido_map)
5. HTMLに保存
tokaido_map.save("tokaido-53.html")
結果

自分の足で箱根越えをしたいですね。
File:NDL-DC 1309891-Utagawa Hiroshige-東海道五拾三次 吉原・左富士-crd.jpg - Wikimedia Commons
また、こちらの浮世絵に描かれているように、13.原宿〜14.吉原宿の間で左側に富士山が見える場所があります。箱根越えの後の楽しみです。

























{kind=link}