今年で最後となる大学入試センター試験が終わりましたね。受験生のみなさまお疲れ様でした。
1日目の倫理では「人間は人工知能(AI)に仕事を奪われると思うか」についての問題が出ました。
人工知能(AI)は
- 計算できないこと
- 統計処理ができないこと
を不得意とします。
つまり「クリエイティブ」なことが不得意です。
来年からは、思考力・判断力・表現力を一層重視する「大学入学共通テスト」に変わります。資料・データから必要な情報を読み取る力や、読み取った情報を比較・組み合わせて課題解決力を問うことを意識した問題も出題されそうです。
将来、AIは今ある仕事の多くを代替するようになるでしょう。しかし、AIが普及することによって、新たに必要となる仕事もあります。そのような仕事に臆せず飛び込むことができるチャレンジ力も大事です。
Face API
さて、話は変わって今回は、Microsoft Azureが提供しているFace APIで顔認識をしてみます。
Face APIは、人の顔を特定するだけでなく、感情認識ができます。人間でも場合によっては読み取ることが難しい感情の状態(幸福、悲しみ、怒り等)を取得することができます。顔認証での出退勤と感情認識を組み合わせて、社員の健康状態管理をするサービスなども出始めています。
また、Face APIは、年齢、性別、眼鏡の有無、ヒゲの有無、姿勢などの分析も行えます。
顔の登録
まずは、認識をする顔の登録をしていきましょう。
1. ライブラリと定数の定義
import json import requests import time import httplib2 import os BASE_URL = 'https://japaneast.api.cognitive.microsoft.com/face/v1.0/' SUBSCRIPTION_KEY = 'サブスクリプションキー' GROUP_ID = 'グループID'
2. Person Groupの作成
API Reference: PersonGroup - Create
# Person Groupの作成 def createPersonGroup(): end_point = BASE_URL + 'persongroups/' + GROUP_NAME headers = { 'Content-Type': 'application/json', 'Ocp-Apim-Subscription-Key': SUBSCRIPTION_KEY, } body = dict() body["name"] = "グループ名" body = str(body) result = requests.put(end_point, data=body, headers=headers) print("Person Group:" + str(json.loads(result.text)))
3. Personの作成
API Reference: PersonGroup Person - Create
# Personの作成 def createPerson(personName): end_point = BASE_URL + 'persongroups/' + GROUP_NAME + '/persons' result = requests.post( end_point, headers = { 'Content-Type': 'application/json', 'Ocp-Apim-Subscription-Key': SUBSCRIPTION_KEY }, json = { 'name': personName } ) print("Person:" + str(json.loads(result.text))) personId = json.loads(result.text)['personId'] return personId
4. Faceの追加
API Reference: PersonGroup Person - Add Face
# Faceの追加 def addDataFaceToPerson(personId, folder): valid_images = [".jpg",".gif",".png"] for f in os.listdir(folder): ext = os.path.splitext(f)[1] if ext.lower() not in valid_images: continue with open(os.path.join(folder,f), 'rb') as f: img = f.read() addFaceImage(personId, img) f.close() def addFaceImage(personId, img): end_point = BASE_URL + 'persongroups/' + GROUP_ID + '/persons/' + personId + '/persistedFaces' result = requests.post( end_point, headers = { 'Content-Type': 'application/octet-stream', 'Ocp-Apim-Subscription-Key': SUBSCRIPTION_KEY }, data=img ) print("Face:" + str(json.loads(result.text)))
5. 学習の実施
API Reference: PersonGroup - Train
# 学習の実施 def trainGroup(): end_point = BASE_URL + 'persongroups/' + GROUP_ID + '/train' result = requests.post( end_point, headers = { 'Ocp-Apim-Subscription-Key': SUBSCRIPTION_KEY }, json = { 'personGroupId': GROUP_ID } ) print("Train:" + str(result))
6. 実行

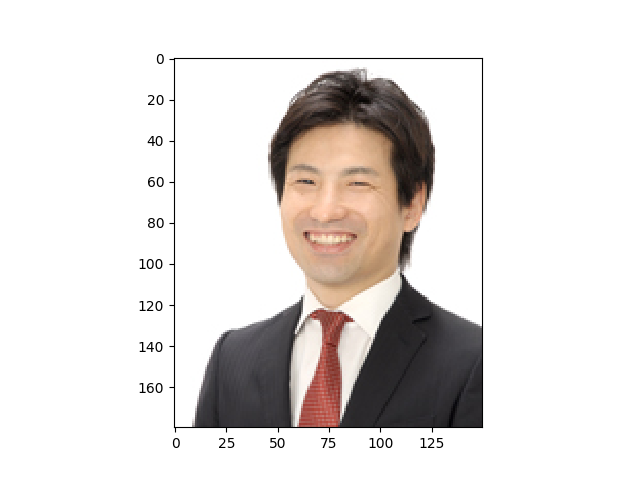
今回も弊社の取締役(陽治郎さん)の写真を使わせていただきます!
3枚程度学習すれば認識ができるようになります。
if __name__ == '__main__': # Person Groupの作成 createPersonGroup() # Personの作成 personId = createPerson('Yojiro') # Faceの追加 addDataFaceToPerson(personId, os.path.join("data", "Yojiro")) time.sleep(5) # 学習の実施 trainGroup()
顔の認識
次は顔の認識をしてみましょう。
1. ライブラリと定数の定義
import json import requests import os BASE_URL = 'https://japaneast.api.cognitive.microsoft.com/face/v1.0/' SUBSCRIPTION_KEY = 'サブスクリプションキー' GROUP_ID = 'グループID'
2. 顔検出
API Reference: Face - Detect
# 顔検出 def detectFaceImage(imgPath): with open(imgPath, 'rb') as f: img = f.read() params = { 'returnFaceId': 'true', 'returnFaceLandmarks': 'false', 'returnFaceAttributes': 'age,blur,emotion,exposure,facialHair,gender,glasses,hair,headPose,makeup,noise,occlusion,smile' } end_point = BASE_URL + "detect" result = requests.post( end_point, params=params, headers = { 'Content-Type': 'application/octet-stream', 'Ocp-Apim-Subscription-Key': SUBSCRIPTION_KEY }, data=img ) detect = json.loads(result.text) print("DetectFace:" + str(detect)) return detect
3. 顔特定
API Reference: Face - Identify
# 顔特定 def identifyPerson(faceId): end_point = BASE_URL + 'identify' faceIds = [faceId] result = requests.post( end_point, headers = { 'Ocp-Apim-Subscription-Key': SUBSCRIPTION_KEY }, json = { 'faceIds': faceIds, 'personGroupId': GROUP_ID } ) candidates = json.loads(result.text)[0]['candidates'] return candidates
4. 名前取得
API Reference: PersonGroup Person - List
# 名前取得 def getPersonNameByPersonId(personId): end_point = BASE_URL + 'persongroups/' + GROUP_ID + '/persons' result = requests.get( end_point, headers = { "Ocp-Apim-Subscription-Key": SUBSCRIPTION_KEY }, json = { 'personGroupId': GROUP_ID } ) persons = json.loads(result.text) for person in persons: if person['personId'] == personId: return person['name']
5. 実行

こちらの陽治郎さんの顔写真を認識してみます。
if __name__ == '__main__': image = os.path.join("test", "Yojiro-test.jpg") # 顔検出 detect = detectFaceImage(image) if len(detect) > 0: for per in detect: detectedFaceId = per['faceId'] emotion = per['faceAttributes']['emotion'] # 顔特定 identifiedPerson = identifyPerson(detectedFaceId) if len(identifiedPerson) > 0 and identifiedPerson[0]['personId']: personId = identifiedPerson[0]['personId'] # 名前取得 personName = getPersonNameByPersonId(personId) print("PersonName:" + str(personName)) else: print("PersonName:Unknown") else: print("Nobody")
実行結果は以下の通りです。
DetectFace:[{'faceId': 'eba5d6ab-cb19-4229-8534-dea32b55f8d9', 'faceRectangle': {'top': 45, 'left': 47, 'width': 57, 'height': 57}, 'faceAttributes': {'smile': 1.0, 'headPose': {'pitch': -2.9, 'roll': 3.4, 'yaw': -15.0}, 'gender': 'male', 'age': 34.0, 'facialHair': {'moustache': 0.1, 'beard': 0.1, 'sideburns': 0.1}, 'glasses': 'NoGlasses', 'emotion': {'anger': 0.0, 'contempt': 0.0, 'disgust': 0.0, 'fear': 0.0, 'happiness': 1.0, 'neutral': 0.0, 'sadness': 0.0, 'surprise': 0.0}, 'blur': {'blurLevel': 'low', 'value': 0.15}, 'exposure': {'exposureLevel': 'goodExposure', 'value': 0.72}, 'noise': {'noiseLevel': 'low', 'value': 0.0}, 'makeup': {'eyeMakeup': False, 'lipMakeup': False}, 'occlusion': {'foreheadOccluded': False, 'eyeOccluded': False, 'mouthOccluded': False}, 'hair': {'bald': 0.09, 'invisible': False, 'hairColor': [{'color': 'black', 'confidence': 0.99}, {'color': 'brown', 'confidence': 0.99}, {'color': 'gray', 'confidence': 0.29}, {'color': 'other', 'confidence': 0.09}, {'color': 'red', 'confidence': 0.03}, {'color': 'blond', 'confidence': 0.03}]}}}]
1個1個属性を見ていきましょう。
年齢(Age): 推定年齢
'age': 34.0ぼかし(Blur): 顔のぼかしの程度
'blur': {'blurLevel': 'low', 'value': 0.15}感情(Emotion): 感情値
'emotion': {'anger': 0.0, 'contempt': 0.0, 'disgust': 0.0, 'fear': 0.0, 'happiness': 1.0, 'neutral': 0.0, 'sadness': 0.0, 'surprise': 0.0}露出(Exposure): 画像内の顔の露出の程度
'exposure': {'exposureLevel': 'goodExposure', 'value': 0.72}顔ひげ(Facial hair): 顔ひげの有無と長さ
'facialHair': {'moustache': 0.1, 'beard': 0.1, 'sideburns': 0.1}性別(Gender): 推定される性別
'gender': 'male'眼鏡(Glasses): 眼鏡があるかどうか
'glasses': 'NoGlasses'髪の毛(Hair): 髪質と髪色
'hair': {'bald': 0.09, 'invisible': False, 'hairColor': [{'color': 'black', 'confidence': 0.99}, {'color': 'brown', 'confidence': 0.99}, {'color': 'gray', 'confidence': 0.29}, {'color': 'other', 'confidence': 0.09}, {'color': 'red', 'confidence': 0.03}, {'color': 'blond', 'confidence': 0.03}]}頭部姿勢(Head pose): 3 次元空間での顔の向き
'headPose': {'pitch': -2.9, 'roll': 3.4, 'yaw': -15.0}化粧(Makeup): 化粧があるかどうか
'makeup': {'eyeMakeup': False, 'lipMakeup': False}ノイズ(Noise): 顔の画像で検出された視覚ノイズ
'noise': {'noiseLevel': 'low', 'value': 0.0}オクルージョン(Occlusion): 顔のパーツをブロックするオブジェクトがあるかどうか
'occlusion': {'foreheadOccluded': False, 'eyeOccluded': False, 'mouthOccluded': False}笑顔(Smile): 笑顔表現
'smile': 1.0
笑顔100点満点ですね!
PersonName: Yojiro
顔の認識結果も「Yojiro」となり、正しく認識できています。
変装チャレンジ
ここからは、陽治郎さんすみません。陽治郎さんを色々と変装させてみます。
正しく認識できるでしょうか。
かぶりもの

PersonName: Yojiro
正しく認識できています。

PersonName: Yojiro
こちらも正しく認識できています。
ひげ

PersonName: Unknown
残念ながら、認識できませんでした。
'facialHair': {'moustache': 0.6, 'beard': 0.6, 'sideburns': 0.4}
顔ひげの属性値が高くなっています。
眼鏡

PersonName: Unknown
こちらも、認識できませんでした。
'glasses': 'Sunglasses'
サングラスは認識しています。
ジョーカー

Nobody
もはや顔として認識されませんでした。
Face API の価格
Face APIにはFreeインスタンスとStandardインスタンスがあります。Freeインスタンスは無料で使えますが、トランザクション数は毎月3万回までに制限されます。Standardインスタンスはトランザクション数の制限はなくなりますが、トランザクション数が増えるにつれて料金が高くなります。お試しで使いたいときはFreeインスタンスを選ぶことがおすすめです。
以上です。
ありがとうございました!