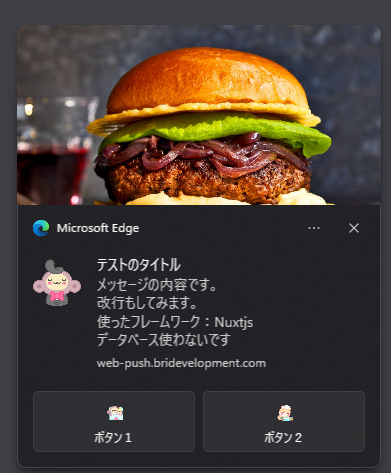
② IAMのroleの設定について ダッシュボードを表示するには、SDKにある「GenerateEmbedUrlForAnonymousUser」を実装する必要があります。
ただし、「GenerateEmbedUrlForAnonymousUser」が実行できるために、次のようなユーザーにロールを与える必要があります。
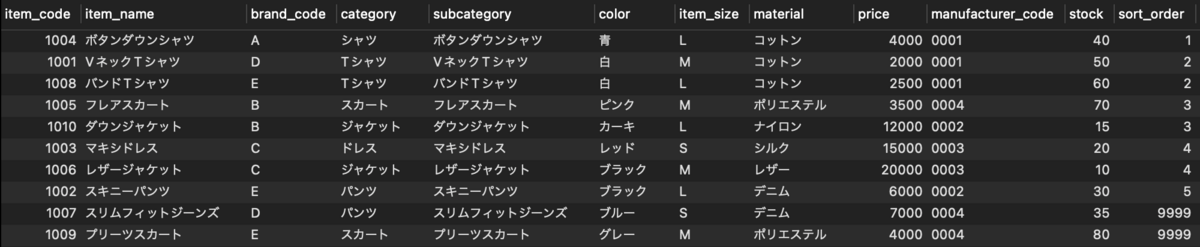
SELECT result.*
FROM (
SELECT item.*,
COALESCE(LEAST(sort_brand.sort, sort_manufacturer.sort), sort_brand.sort, sort_manufacturer.sort, 9999) AS sort_order
FROM item
LEFTJOIN sort AS sort_brand ON item.brand_code = sort_brand.code AND sort_brand.sort_type = 1LEFTJOIN sort AS sort_manufacturer ON item.manufacturer_code = sort_manufacturer.code AND sort_manufacturer.sort_type = 2
) AS result
ORDERBY result.sort_order, result.item_code;
If the response has a Last-Modified header field (Section 2.2 of
[RFC7232]), caches are encouraged to use a heuristic expiration value
that is no more than some fraction of the interval since that time.
A typical setting of this fraction might be 10%.