毎日暑いですね。今回はサクッとSQLについてです。
やりたいこと
商品マスタテーブル(MySQL)の項目に特定の値がセットされている商品を販売サイトの上位に表示させて利用者におすすめしたい。
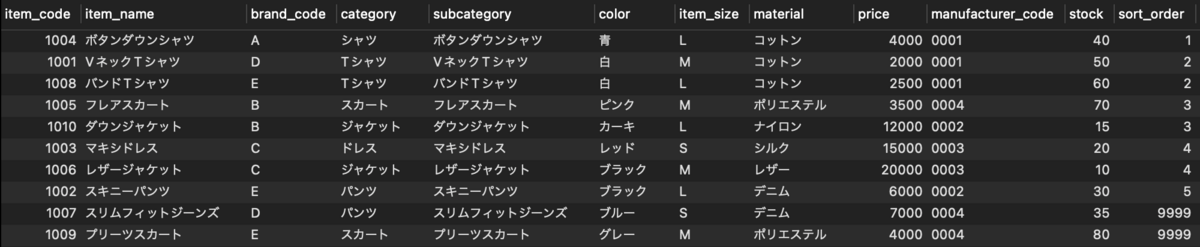
商品マスタデータ

この商品マスタのデータについて
- ブランドA、B、Cを上位に表示したい。
- XXX製、YYY製、ZZZ製を上位に表示したい。
- ブランドA → XXX製 → ブランドB → ブランドC → YYY製 → ZZZ製 の順に表示したい。
- 同じ表示順位の場合は、商品ID順に表示したい。
どのように実現するか。
並び順マスタ
以下のような並び順マスタを用意します。

テーブル作成・データ登録のSQL
①商品マスタ(item)テーブルの作成
CREATE TABLE item ( item_code INT PRIMARY KEY, --商品ID item_name VARCHAR(255), --商品名 brand_code CHAR(1), --ブランド category VARCHAR(255), --カテゴリ subcategory VARCHAR(255), --サブカテゴリ color VARCHAR(255), --色 item_size CHAR(1), --サイズ material VARCHAR(255), --素材 price INT, --価格 manufacturer_code VARCHAR(4), --製造元 stock INT --在庫数 )
②並び順マスタ(sort)テーブルの作成
CREATE TABLE sort ( id INT PRIMARY KEY, --ID sort_type INT, --区分 code VARCHAR(10), --コード name VARCHAR(255), --名称 sort INT --並び順 )
③商品マスタ(item)へのデータ登録
INSERT INTO item (item_code, item_name, brand_code, category, subcategory, color, item_size, material, price, manufacturer_code, stock) VALUES (1001, 'VネックTシャツ', 'D', 'Tシャツ', 'VネックTシャツ', '白', 'M', 'コットン', 2000, '0001', 50), (1002, 'スキニーパンツ', 'E', 'パンツ', 'スキニーパンツ', 'ブラック', 'L', 'デニム', 6000, '0002', 30), (1003, 'マキシドレス', 'C', 'ドレス', 'マキシドレス', 'レッド', 'S', 'シルク', 15000, '0003', 20), (1004, 'ボタンダウンシャツ', 'A', 'シャツ', 'ボタンダウンシャツ', '青', 'L', 'コットン', 4000, '0001', 40), (1005, 'フレアスカート', 'B', 'スカート', 'フレアスカート', 'ピンク', 'M', 'ポリエステル', 3500, '0004', 70), (1006, 'レザージャケット', 'C', 'ジャケット', 'レザージャケット', 'ブラック', 'M', 'レザー', 20000, '0003', 10), (1007, 'スリムフィットジーンズ', 'D', 'パンツ', 'スリムフィットジーンズ', 'ブルー', 'S', 'デニム', 7000, '0004', 35), (1008, 'バンドTシャツ', 'E', 'Tシャツ', 'バンドTシャツ', '白', 'L', 'コットン', 2500, '0001', 60), (1009, 'プリーツスカート', 'E', 'スカート', 'プリーツスカート', 'グレー', 'M', 'ポリエステル', 4000, '0004', 80), (1010, 'ダウンジャケット', 'B', 'ジャケット', 'ダウンジャケット', 'カーキ', 'L', 'ナイロン', 12000, '0002', 15);
④並び順マスタ(sort)へのデータ登録
INSERT INTO sort (id, sort_type, code, name, sort) VALUES (1, 1, 'A', 'ブランドA', 1), (2, 1, 'B', 'ブランドB', 3), (3, 1, 'C', 'ブランドC', 4), (4, 2, '0001', 'XXX製', 2), (5, 2, '0002', 'YYY製', 5), (6, 2, '0003', 'ZZZ製', 6)
商品データ表示用SQL
・ブランドA、B、Cを上位に表示したい。
・XXX製、YYY製、ZZZ製を上位に表示したい。
・ブランドA → XXX製 → ブランドB → ブランドC → YYY製 → ZZZ製 の順に表示したい。
・同じ表示順位の場合は、商品ID順に表示したい。
上記の並び順を実現するSQLは以下となります。
SELECT result.* FROM ( SELECT item.*, COALESCE(LEAST(sort_brand.sort, sort_manufacturer.sort), sort_brand.sort, sort_manufacturer.sort, 9999) AS sort_order FROM item LEFT JOIN sort AS sort_brand ON item.brand_code = sort_brand.code AND sort_brand.sort_type = 1 LEFT JOIN sort AS sort_manufacturer ON item.manufacturer_code = sort_manufacturer.code AND sort_manufacturer.sort_type = 2 ) AS result ORDER BY result.sort_order, result.item_code;
<解説>
- サブクエリで全ての商品マスタ(item)のデータを取得します。
- 各商品データについて、ブランド(brand)と製造元(manufacturer)の並び順(sort)を検索します。
2.1 両方の並び順が存在する場合は、LEAST関数により小さい方(並び順が上位の方)が選ばれます。
2.2 一方だけが存在する場合は、存在する方の並び順が選ばれます。
2.3 どちらも存在しない場合は、9999が選ばれます。 - このサブクエリの結果を使って、全ての商品をソートします。ソートは、2で選ばれた並び順(sort_order)で行われ、並び順が同じ商品の場合は、商品ID(item_code)でソートします。これにより、最終的な商品リストが生成されます。
フレキシブルですね。