昨年末に2回ほど、GAS & slackの記事を書かせていただきました。
昨年末に2回ほど、GAS & slackの記事を書かせていただきました。
GAS & SlackでMeetのリンク自動生成Botを作ってみた - Briswell Tech Blog
GAS & Slackで地震発生時の安否確認Botを作ってみた - Briswell Tech Blog
私自身プログラマではないため、記事を書くにあたってスクリプトの作成が肝だったりします。
というよりスクリプト組めなくて諦めた記事がいくつかあったりします。。。
そこで、今回は最近流行りのChatGPTを使うことで、この悩みが解消されるのでは?と思い実際にやってみた次第です。
プログラムとかよくわからないけど、ChatGPTを使って色々自動化したいなんて人の参考になれば幸いです。
今回実装したのは、定期投稿botで投稿条件は以下となります。
* 毎週木曜日にslackの特定のチャンネルに投稿する
* 木曜日が祝日だった場合は水曜日に投稿する
* 年末年始(12/28 ~ 1/3)は投稿しない
※今回の目的はChatGPTでどこまでできるかなので簡易的な要件を選んでいます。
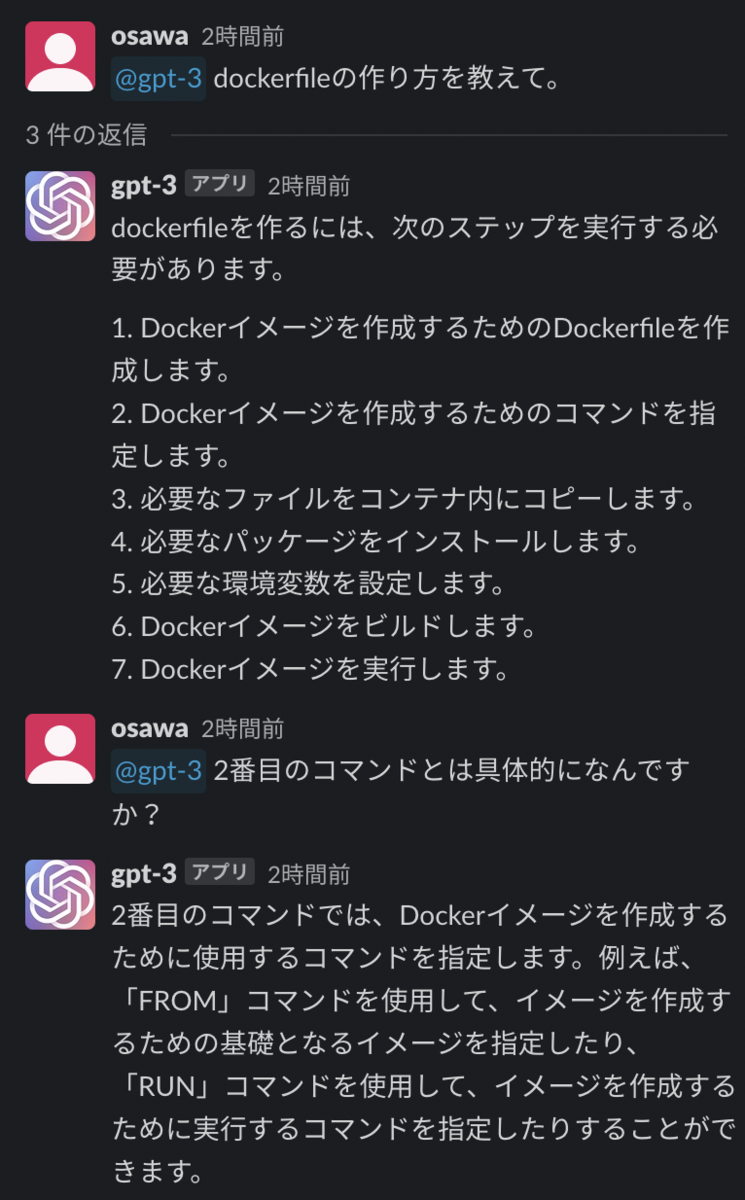
ChatGPTでコード生成(失敗例)
今回はさっそくスクリプトの生成から行なっていきます。
ChatGPT
ChatGPTにスクリプトを組んでもらうため、仕様(やりたいこと)を伝える必要があります。
実際にChatGPTに投げた内容は以下になります。
以下の要件を網羅したgoogle apps scriptのScriptを作成してください
なお、VERIFICATION_TOKENとBOT_USER_OAUTH_TOKENは既に取得済みであるものとする
本処理はgoogle apps scriptの日次トリガーで実行されるものとする
祝日の取得には以下のカレンダーIDを使用すること
ja.japanese#holiday@group.v.calendar.google.com
分岐1: 実行日が年末年始(12月28日 ~ 1月3日)ではない
yes → 分岐2へ
no → 処理終了
分岐2: 実行日の曜日を確認する
実行日が水曜日である → 分岐3へ
実行日が木曜日である → 分岐4へ
上記以外の曜日である → 処理終了
分岐3: 実行日翌日が祝日である
yes → 分岐4へ
no → 処理終了
分岐4: 実行日が祝日である
yes → 処理終了
no → slackの特定のチャンネルへ通知を出す
通知内容は以下とする
「<!channel>\nおはようございます。\n退社までに本日分までの工数入力をお願いします。」
そして実際に作成されたスクリプトがこちらです。
function myFunction() {
const VERIFICATION_TOKEN = "XXXXXXXXXX";
const BOT_USER_OAUTH_TOKEN = "xoxb-XXXXXXXXXX";
const CHANNEL_ID = "XXXXXXXXXX";
const CALENDAR_ID = "ja.japanese#holiday@group.v.calendar.google.com";
const now = new Date();
const yearEndStart = new Date(now.getFullYear(), 11, 28);
const newYearEnd = new Date(now.getFullYear() + 1, 0, 3);
const isYearEnd = now >= yearEndStart && now <= newYearEnd;
const dayOfWeek = now.getDay();
if (!isYearEnd) {
if (dayOfWeek === 3) {
const tomorrow = new Date(now.getFullYear(), now.getMonth(), now.getDate() + 1);
const calendar = CalendarApp.getCalendarById(CALENDAR_ID);
const events = calendar.getEventsForDay(tomorrow);
const isTomorrowHoliday = events.length > 0;
if (isTomorrowHoliday) {
sendSlackMessage("<!channel>\nおはようございます。\n退社までに本日分までの工数入力をお願いします。", VERIFICATION_TOKEN, BOT_USER_OAUTH_TOKEN, CHANNEL_ID);
}
} else if (dayOfWeek === 4) {
sendSlackMessage("<!channel>\nおはようございます。\n退社までに本日分までの工数入力をお願いします。", VERIFICATION_TOKEN, BOT_USER_OAUTH_TOKEN, CHANNEL_ID);
}
}
}
}
function sendSlackMessage(message, verificationToken, botUserOauthToken, channelId) {
const url = "https://slack.com/api/chat.postMessage";
const headers = {
"Content-type": "application/json",
"Authorization": "Bearer " + botUserOauthToken,
};
const payload = {
"text": message,
"channel": channelId,
};
const options = {
"method": "post",
"headers": headers,
"payload": JSON.stringify(payload),
};
UrlFetchApp.fetch(url, options);
}
}
なかなか良さそうなのですが、木曜日の場合に祝日判断が抜けている。。。
ChatGPTが生成したコードに追記して完成させる
ということで、木曜日が祝日の場合にskipする処理を追記します。
追記したものがこちらになります。
※当方がプログラマではないのでコーディングに無駄があるかもしれませんがご容赦ください。
function myFunction() {
const VERIFICATION_TOKEN = "XXXXXXXXXX";
const BOT_USER_OAUTH_TOKEN = "xoxb-XXXXXXXXXX";
const CHANNEL_ID = "XXXXXXXXXX";
const CALENDAR_ID = "ja.japanese#holiday@group.v.calendar.google.com";
const now = new Date();
const yearEndStart = new Date(now.getFullYear(), 11, 28);
const newYearEnd = new Date(now.getFullYear() + 1, 0, 3);
const isYearEnd = now >= yearEndStart && now <= newYearEnd;
const dayOfWeek = now.getDay();
if (!isYearEnd) {
if (dayOfWeek === 3) {
const tomorrow = new Date(now.getFullYear(), now.getMonth(), now.getDate() + 1);
const calendar = CalendarApp.getCalendarById(CALENDAR_ID);
const events = calendar.getEventsForDay(tomorrow);
const isTomorrowHoliday = events.length > 0;
if (isTomorrowHoliday) {
sendSlackMessage("<!channel>\nおはようございます。\n退社までに本日分までの工数入力をお願いします。", VERIFICATION_TOKEN, BOT_USER_OAUTH_TOKEN, CHANNEL_ID);
}
} else if (dayOfWeek === 4) {
const today = new Date(now.getFullYear(), now.getMonth(), now.getDate());
const calendar = CalendarApp.getCalendarById(CALENDAR_ID);
const events = calendar.getEventsForDay(today);
const isTodayHoliday = events.length = 0;
if (isTodayHoliday) {
}else{
sendSlackMessage("<!channel>\nおはようございます。\n退社までに本日分までの工数入力をお願いします。", VERIFICATION_TOKEN, BOT_USER_OAUTH_TOKEN, CHANNEL_ID);
}
}
}
}
function sendSlackMessage(message, verificationToken, botUserOauthToken, channelId) {
const url = "https://slack.com/api/chat.postMessage";
const headers = {
"Content-type": "application/json",
"Authorization": "Bearer " + botUserOauthToken,
};
const payload = {
"text": message,
"channel": channelId,
};
const options = {
"method": "post",
"headers": headers,
"payload": JSON.stringify(payload),
};
UrlFetchApp.fetch(url, options);
}
}
実際に動作確認をしてみます。
const VERIFICATION_TOKEN = "XXXXXXXXXX";
const BOT_USER_OAUTH_TOKEN = "xoxb-XXXXXXXXXX";
const CHANNEL_ID = "XXXXXXXXXX";
上記3つのパラメータ値の設定を忘れずに行いましょう(設定方法は過去の記事を参照してください)。
GAS & SlackでMeetのリンク自動生成Botを作ってみた - Briswell Tech Blog
検証は以下の日付を指定することで水曜日や木曜日を待たずに検証できます。
「実施日」
const now = new Date(); の括弧内に日付をセットすることで該当日で検証可能です。
const now = new Date(2023, 2, 21); // 2023年3月21日で検証する場合の書き方
※月は0始まり(0 = 1月、11 = 12月)でセットします
「曜日」
if (dayOfWeek === 3) の数値を変更することで曜日を変えて検証可能です。
if (dayOfWeek === 2) // 火曜日で検証したい場合の書き方
※曜日は0始まり(0 = 日曜日、6 = 土曜日)でセットします
検証してみて、投稿ができていることを確認できました。
また、祝前日投稿や祝日に投稿しない条件もバッチリでした。

苦労した点
ここからは余談になりますが、ChatGPTでスクリプト生成で苦労した点を残しておきます。
- 生成するたびに異なるスクリプトを組んでくる
- 回答の文字数に制限があるのでスクリプト途中で回答が終了する(有料プラン入れってことですね)
- 完璧に仕様を網羅できていない
ちなみに、最終版のスクリプトになるまで何度も生成を繰り返してました。
また、仕様を網羅できていない点については、ChatGPTへの渡し方(伝え方)で解決できるのかもしれません。
最後に
当初は依頼を投げたらそれっぽいスクリプトを返してくれるのですごく便利なのでは?と思っていたのですが、
実際取り組んでみると、多少のコツであったり知見(生成されたスクリプトが正しいかどうかの判断)がないと厳しいかもしれません。
とはいえ、このレベルであればわざわざプログラマの方を捕まえなくてもよくなったのは非常に良いことだと思います。
ChatGPTへの橋渡しをする職業(コミュニケーター)が今後は出てきたり資格ができたりするんでしょうか。。。
なにはともあれ、ブログの記事が捗りそうですね!