こんにちは.AI,IoT担当の大澤です.
最近AI界隈では文章から画像を生成するText to Imageタスクの分野で大変な盛り上がりを見せていました. OpenAIのDALL-E2やGoogleのImagenなど,高画質で高精度な画像を生成するモデルが相次いで発表されたことが大きいのではないでしょうか.
Text to Imageとは読んで字のごとく,入力された文字列をもとに画像を生成するタスクのことです.下の画像を見てみましょう.

麦わら帽子とサングラスを身に着けたサボテンですね.Photoshopで作られた作品のように見えますが…実はこちら,Googleが発表したImagenというAIが作成したものです.
こちらはまずAIへの入力として「A small cactus wearing a straw hat and neon sunglasses in the Sahara desert.」という文章が与えられます.日本語訳では「サハラ砂漠で麦わら帽子をかぶり、ネオンサングラスをかけた小さなサボテン。」です.
するとこの画像が出力されるわけです.しっかりと文章の意味を理解し,的確に画像へと変換されています.
「A photo of a Corgi dog riding a bike in Times Square. It is wearing sunglasses and a beach hat.(タイムズスクエアで自転車に乗っているコーギー犬の写真。サングラスとビーチハットをかぶっています。)」という文章を与えると次のような画像が生成されるようです.

面白いですね.実は今までにもこのようなタスクができるモデルはあったのですが,transformerや拡散モデルなど,近年生まれた技術の組み合わせでここまでクオリティの高い画像生成を行うことができるようになったようです.
ただ,これらは膨大な計算リソースを必要とするため,一般的なPCなどでは実行できません.代わりに計算量を大幅に削減したモデルで,画像生成を体験してみましょう.
こちらのサイトに掲載されているgooglecolabのdemoコードを使用させていただきました.
まずはimagenのサイトにもあった文章と同じものを入れてみましょう.
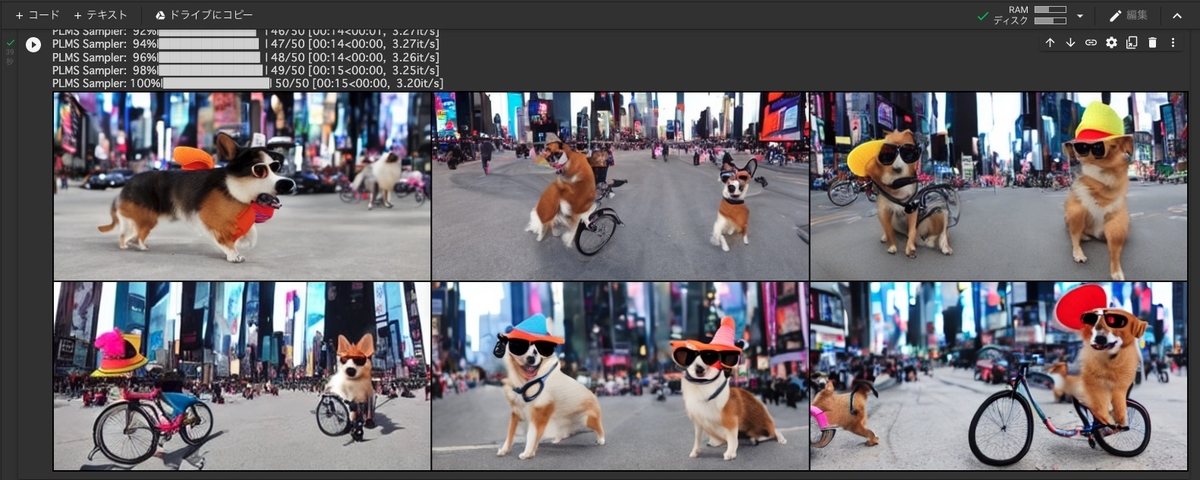
流石にGoogleのようにはいきませんが,それっぽく見える画像が生成できました.
他にも色々試してみましょう.

真ん中上部のガッツポーズが最高ですね.

左下のボケ感がじわじわきますね.

イラスト風にもできました.
とてもおもしろいですね.夏なのでサングラス多めでお送りしました. それでは.